Please note that before compiling you need to set below configurations, in Project settings.
Device : PIC16F84A
MCU Clock : 8.000000MHz
Once you have the .hex file generated from MikroC compiler, let's move to Proteus to build the circuit for simulation and PCB layout generation.
Proteus Schematic:
Once schematic is completed please set CRYSTAL value to 8MHz and double click on PIC16F84A to set clock frequency and to load generated .hex file from MikroC compiler. Now you can start the simulation to verify the output.
Using MPLAB you can load the generated .hex file to PIC16F84A micro-controller using Pickit 3 programmer.
Next Let's generate PCB layout using the same schematic we built.
PCB Layout:
Next we'll generate actual PCB from the above PCB layout using Toner transfer and etching technique.
Wash and clean copper board so that there are no oxides left in copper layer. (Till it gets shiny)
Print PCB layout to a Magazine paper.
Place the magazine paper(printed side) on top of copper board and apply masking tape to stop sliding.
Next apply nail polish remover liquid to the magazine paper and gently rub the paper, so that toner will attached to the copper layer. Please do this about 10mins covering the whole printed area, specially in each schematic path.
Once above done, slowly remove the Magazine paper, and you will notice how toner attached to copper board along with some residue paper also.
Next you can wash residue paper and get clean schematic paths in copper layer.
In any case if a path is broken, fix the broken path using a permanent marker pen.
Now submerge the copper board in a FeCl3 (Ferric Chloride) liquid and slowly shake it using some hand tool.
Once the unwanted copper disappear completely, wash the copper board and remove applied toner, such that you will have only schematic copper paths.
Next solder each and every component and apply 5V power supply, to get this functional.
In this post I will show you how to make a Christmas decoration with blinking LEDs and a background music using Arduino Mega 2560.
You need to connect piezo buzzer to the 12th pin and LEDs from 22 to 52 pins as configured in the code.
LEDs should connect to Arduino pins based on the levels shown below.
As shown in the video you can use similar STAR using plastic sheet to pin 21 LEDs for this decoration.
Note: In order to change the brightness of LEDs and sound of the buzzer, use appropriate resistors serial with load. (Eg : 220 ohm resister for each LED and 100 ohm resister for buzzer)
You can see which LED will fall into which level from the Arduino code.
Music was generated using Arduino tone function. After each note, one LED level will be switched ON, while others remain OFF, which will be continued throughout the entire song.
Music notes frequencies were generated by the formula mentioned in below reference.
Here, in order to understand how each note plays, notes were written one by one, which makes the code bigger.
If you are sure about the musical notes, just place them in an array, along with weights of each note in a similar size another array, and play them using tone function inside a for loop.
Eg:
// Musical Notes #define G1 196 #define A1 220 #define B1 247 #define C 261 #define D 294 #define E 329 #define F 349 #define G 392 #define A 440 #define B 493 #define C2 523
int notes = {G, G, G, C, B, ....}
int weights = {0.5, 0.5, 1, 1, 2, ....}
Arduino Code
// Musical Notes #define G1 196 #define A1 220 #define B1 247 #define C 261 #define D 294 #define E 329 #define F 349 #define G 392 #define A 440 #define B 493 #define C2 523
Bucket sort, or bin sort, is a sorting algorithm that works by partitioning an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm. (Wikipedia)
Worst case performance - O(n^2)
Bucket Sort
C++
void bucket_sort(int array[], int length) { int k = max_value(array,length); int bucket[k+1]; for(int i=0; i<=k; i++) { bucket[i] = 0; } for(int j=0; j<length; j++) { bucket[array[j]]++; } int index = 0; for (int i=0; i<=k; i++) { for (int j=0; j<bucket[i]; j++) { array[index++]=i; } } }
int max_value(int array[], int length) { int max = 0; for (int i = 0; i < length; i++) if (max < array[i]) max = array[i]; return max; }
Java
public int[] bucket_sort(int[] array) { int k = max_value(array); int[] bucket = new int[k+1]; for (int j = 0; j < array.length; j++) { bucket[array[j]]++; } int index = 0; for (int i = 0; i < bucket.length; i++) { for (int j = 0; j < bucket[i]; j++) { array[index++] = i; } } return array; }
public int max_value(int[] array) { int max = 0; for (int i = 0; i < array.length; i++) { if (max < array[i]) { max = array[i]; } } return max; }
Matlab
function array = bucket_sort(array) k = max(array); bucket = zeros(1,k+1); B = zeros(1,numel(array)); for j = 1:numel(array) bucket(array(j)) = bucket(array(j)) + 1; end index = 1; for i = 1:k+1 for j = 1:bucket(i) array(index) = i; index = index + 1; end end end
Python
def bucket_sort(array): k = max(array) bucket = [0]* (k+1) for j in range(len(array)): bucket[array[j]] = bucket[array[j]] + 1 index = 0 for i in range(k+1): for j in range(bucket[i]): array[index] = i index = index + 1
Shell sort is an in-place comparison sort. It can be seen as either a generalization of sorting by exchange (bubble sort) or sorting by insertion (insertion sort). Shell sort starts by sorting pairs of elements far apart from each other, then progressively reducing the gap between elements to be compared. (Wikipedia)
Worst case performance - O(n^2)
Shell sort
C++
void shell_sort(int array[], int length) { for (int gap = length/2; gap > 0; gap /= 2) { for (int i = gap; i < length; i += 1) { int temp = array[i]; int j; for (j = i; j >= gap && array[j - gap] > temp; j -= gap) array[j] = array[j - gap]; array[j] = temp; } } }
Java
public int[] shell_sort(int[] array) { for (int gap = array.length / 2; gap > 0; gap /= 2) { for (int i = gap; i < array.length; i += 1) { int temp = array[i]; int j; for (j = i; j >= gap && array[j - gap] > temp; j -= gap) { array[j] = array[j - gap]; } array[j] = temp; } } return array; }
Matlab
function array = shell_sort(array) length = numel(array); gap = floor(length/2); while gap > 0 for i = gap+1:length temp = array(i); j = i; while (j >= gap+1) && (array(j-gap) > temp) array(j) = array(j-gap); j = j - gap; end array(j) = temp; end gap = floor(gap/2); end end
Python
import math
def shell_sort(array): length = len(array) gap = math.floor(length/2) while gap > 0: for i in range(gap,length): temp = array[i] j = i while (j >= gap) and (array[j - gap] > temp): array[j] = array[j-gap] j = j - gap array[j] = temp gap = math.floor(gap/2)
Comb sort is a comparison sorting algorithm improves on Bubble sort. The basic idea is to eliminate turtles, or small values near the end of the list, since in a bubble sort these slow the sorting down tremendously. (Wikipedia)
Comb Sort
Worst case performance - O(n^2)
C++
void comb_sort(int array[], int length) { int gap = length; bool swapped = true; while((gap > 1) || (swapped == true)) { gap /= 1.25; if (gap < 1) { gap = 1; } int i = 0; swapped = false; while (i + gap < length) { if (array[i] > array[i + gap]) { int temp = array[i]; array[i] = array[i + gap]; array[i + gap] = temp; swapped = true; } i++; } } }
Java
public int[] comb_sort(int[] array) { int gap = array.length; boolean swapped = true; while ((gap > 1) || (swapped == true)) { gap /= 1.25; if (gap < 1) { gap = 1; } int i = 0; swapped = false; while (i + gap < array.length) { if (array[i] > array[i + gap]) { int temp = array[i]; array[i] = array[i + gap]; array[i + gap] = temp; swapped = true; } i++; } } return array; }
Matlab
function array = comb_sort(array) gap = numel(array); swapped = true; while (gap > 1) || swapped gap = floor(gap/1.25); if gap < 1 gap = 1; end i = 1; swapped = false; while (i+gap-1) < numel(array) if array(i) > array(i+gap) array([i i+gap]) = array([i+gap i]); swapped = true; end i = i + 1; end end end
Python
import math
def comb_sort(array): gap = len(array) swapped = True while gap > 1 or swapped : gap = math.floor(gap/1.25) if gap < 1 : gap = 1 i = 0 swapped = False while (i+gap)< len(array): if array[i] > array[i + gap]: temp = array[i] array[i] = array[i + gap] array[i + gap] = temp swapped = True i = i + 1
Systolic architecture consists of an array of processing elements, where data flows between neighboring elements, synchronously, from different directions. Processing element takes data from Top, Left and output the results to Right, Bottom.
One of the key application of Systolic architecture is matrix multiplication. Here each processing element performs four operations, namely FETCH, MULTIPLICATION, SHIFT & ADDITION. As following figure depicts, "in_a", "in_b" are inputs to the processing element and "out_a", "out_b" are outputs to the processing element. "out_c" is to get the output result of each processing element.
Processing elements are arranged in the form of an array. In this case we analyze, multiplication of 3x3 matrices, which can be easily extended. Let say the two matrices are A and B. Following figure depicts how matrix A and B are fed into PE(processing element) array.
Simulation of following matrices are as follows.
Verilog modules
module top(clk,reset,a1,a2,a3,b1,b2,b3,c1,c2,c3,c4,c5,c6,c7,c8,c9);
parameter data_size=8;
input wire clk,reset;
input wire [data_size-1:0] a1,a2,a3,b1,b2,b3;
output wire [2*data_size:0] c1,c2,c3,c4,c5,c6,c7,c8,c9;
wire [data_size-1:0] a12,a23,a45,a56,a78,a89,b14,b25,b36,b47,b58,b69;
pe pe1 (.clk(clk), .reset(reset), .in_a(a1), .in_b(b1), .out_a(a12), .out_b(b14), .out_c(c1));
pe pe2 (.clk(clk), .reset(reset), .in_a(a12), .in_b(b2), .out_a(a23), .out_b(b25), .out_c(c2));
pe pe3 (.clk(clk), .reset(reset), .in_a(a23), .in_b(b3), .out_a(), .out_b(b36), .out_c(c3));
pe pe4 (.clk(clk), .reset(reset), .in_a(a2), .in_b(b14), .out_a(a45), .out_b(b47), .out_c(c4));
pe pe5 (.clk(clk), .reset(reset), .in_a(a45), .in_b(b25), .out_a(a56), .out_b(b58), .out_c(c5));
pe pe6 (.clk(clk), .reset(reset), .in_a(a56), .in_b(b36), .out_a(), .out_b(b69), .out_c(c6));
pe pe7 (.clk(clk), .reset(reset), .in_a(a3), .in_b(b47), .out_a(a78), .out_b(), .out_c(c7));
pe pe8 (.clk(clk), .reset(reset), .in_a(a78), .in_b(b58), .out_a(a89), .out_b(), .out_c(c8));
pe pe9 (.clk(clk), .reset(reset), .in_a(a89), .in_b(b69), .out_a(), .out_b(), .out_c(c9));
endmodule
module pe(clk,reset,in_a,in_b,out_a,out_b,out_c);
parameter data_size=8;
input wire reset,clk;
input wire [data_size-1:0] in_a,in_b;
output reg [2*data_size:0] out_c;
output reg [data_size-1:0] out_a,out_b;
always @(posedge clk)begin
if(reset) begin
out_a=0;
out_b=0;
out_c=0;
end
else begin
out_c=out_c+in_a*in_b;
out_a=in_a;
out_b=in_b;
end
end
endmodule
Output results can be seen after6 clock periods from the time of data insertion. (time period between a1 gets 1 and the time of yellow marker). In usual case for 3x3 matrix multiplication altogether, it takes 3x3x3 = 27 times to do the iterations and calculations. But in this case it takes lesser time (x6 times), because systolic architecture is a class of parallel pipe-lined architecture. Here is the synthesis report and timing constraints of the RTL.
Target device - xc3s500e-4fg320
Tool used - Xilinx ISE 14.3
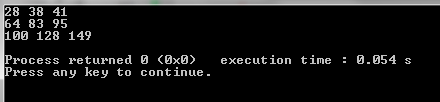
Now lets analyze the timing differences between above hardware design and the algorithm written in C++.
C++
#include<iostream>
using namespace std;
int main()
{
int a[3][3] =
{
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};
int b[3][3] =
{
{2, 1, 3},
{4, 5, 7},
{6, 9, 8}
};
int c[3][3];
int sum;
for(int i = 0; i < 3; i++)
{
for(int j = 0; j < 3; j++)
{
sum = 0;
for(int k = 0; k < 3; k++)
{
sum += a[i][k] * b[k][j];
}
c[i][j] = sum;
}
}
for(int i = 0; i < 3; i++)
{
for(int j = 0; j < 3; j++)
{
cout <<c[i][j]<<" ";
}
cout << endl;
}
return 0;
}
Output results
C++ execution time = 0.054s Total delay of digital design = 7.765ns x 6 = 46.59ns